
Iowa Gambling Task¶
Introduction¶
The main idea behind the Iowa Gambling Task is to test participant’s decision making using four cards. The participants taking part in the game have a choice of four cards (A,B,C,D). Depending on the card chosen and chance, the participants can gain or lose money. Each deck has a different probability of winning/losing. This means that there is one or two decks either {A,B,C,D} that is more favourable to the participants than the others. The idea behind the game is that depending on how a participant plays the game allows the observer to figure out psychological attributes that they might have.
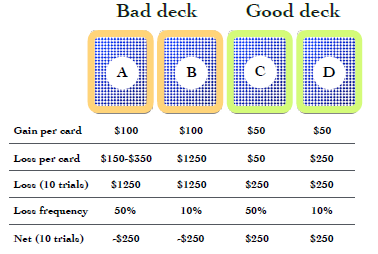
Note
The task was originally developed to detect problems that participants could have had with their ventromedial prefrontal cortex
Clustering Techniques¶
For the purpose of this assignment I will be focusing mainly on the k-means clustering technique. K-means aims at partitioning x abservations into y clusters where each cluster is calculated based on a common mean. I will also run the elbow method of the dataset. The elbow method runs k-means clustering on the dataset for a range of values (say from 1-10) and then for each value of k computes an average score for all clusters. This then basically tells us what the optimum amount of clusters is.
Data Overview¶
All of the data you will see used in this project is data that has been taken from 617 participants taking part in the Iowa Gambling Task. The participants all completed the challenge as a computerized version. The participants taking part were part of 10 seperate studies. The data itself is the winnings/losses of the participants along with their study and choices. The data can be found in csv format, I plan on reading the data in using the pandas library and merging all of the csv files together for a more total clustering result.